ABSTRACT: This paper will give an understanding of search engines and related technologies with the help of Google platform, how they affect communication, business and how they are changing our understanding of information and knowledge. This will also focus on how search takes place, what is Custom Search and how a custom search engine can be created. Custom search engines based on web crawling algorithm are considered.
1. INTRODUCTION
|
he main problem of world wide web is with an estimated 800 million web pages finding the page we want is difficult!
A Search Engine is an information retrieval system designed to help find information stored on a computer system, such as on the World Wide Web. i.e, It is a Searchable online Database of Internet resources. The Search Engine allows the users to ask for content meeting specific criteria and retrieves a list of items that match those criteria.
This report studies how to use custom search engines on Google platforms and what impact it has on the users, what requirements it expects from the web crawlers.
2. Proposed scheme
In this scheme, the applications involve several services like Robot, who collects pages and checks for page changes; Indexer which is used to constructs a sophisticated file structure to enable fast page retrieval, Searcher which satisfies user queries
This project presents a framework intended to help users in the task of searching the web pages, which puts the emphasis on an experimental evaluation of the cost of using such a framework.
Pages get into a Search Engine by means of Robot discovery (following links), Self submission and Payments.

3. Web Crawling
A web crawler is a program or automated script which browses the World Wide Web in a methodical, automated manner. i.e., it is a means of providing up-to-date data. Mainly it used to create a copy of all the visited pages for later processing by a search engine.
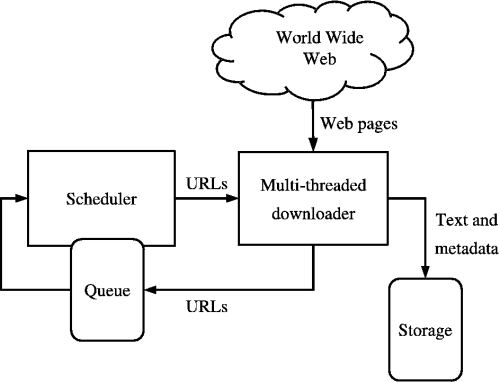
Web Crawlers:
First web crawlers start with known sites. Then record information for these sites and follow the links from each site. Record information found at each site. Repeat the process for all the sites.
Web Crawling Algorithm:
Put a set of known sites on a queue.
Repeat the following until the queue is empty:
Take the first page off of the queue
If this page has not yet been processed:
Record the information found on this
Page: Positions of words, links going out.
Add each link on the current page to the Queue.
Record that this page has been processed.
4. System Design
Custom search engine consist operations as Crawling, Searching and ranking.
Searching:
Searching a document consists the following:
Parse query.
Convert words into wordIDs.
Identify a barrel for Word.
Scan doc lists until a doc that matches all the search words is found.
Take in a query, determine which pages match,
and show the results (ranking and display of results).
Indexing:
Indexing is used to organize the contents of the pages in a way that allows efficient retrieval. Search Engine Indexing entails how data is collected, parsed, and stored to facilitate fast and accurate retrieval. The goal of storing an index is to optimize the speed and performance of finding relevant documents for a search query.
Index design factors are: Storage techniques, Index size, Lookup speed, Fault tolerance, Maintenance.
Ranking:
For a single word, identify the hit list and its type; count the # of hits of each type. Combine with Page Rank. For multiple words, take proximity into account.
5. Conclusion:
Thus, a Google Custom Search Engine (CSE) is a specialized search engine that provides superior results for searches pertaining to its particular subject by combining human expertise with Google's standard search algorithm.
This report analyses how to design custom search engine by applying web crawling algorithm.
CSE program allows four major methods for altering the search results as, which sites will be included in the displayed results? Sites whose ranking should be raised? Sites whose ranking should be lowered, Sites which should be excluded from the results?
For the future work, the activity of Generalizing the approach that meet all the above methods, should be implemented.